Case Study
AI-Powered Data Extraction for Leasing Documents
Softwise.AI designed and delivered an automated data extraction system for Europejski Fundusz Leasingowy (EFL), one of Poland's leading leasing companies and part of the Credit Agricole Group. Built on Azure and large language models, the solution replaces a manual monthly process of reviewing around 100 leasing documents with an end-to-end pipeline that turns a raw batch into a complete, standardized report in minutes - while meeting the strict banking, RODO, and group-level compliance requirements.
CLIENT
EFL
YEAR
2026
INDUSTIRES
Financial Services Leasing
DELIVERABLES
AI Data Extraction Pipeline, Azure Architecture, LLM Prompt Engineering, Production Operationalization

The problem
EFL operates in a highly competitive and regulated leasing environment, where ongoing market monitoring requires regular analysis of competitor and partner documentation.
Until now, that monitoring meant a manual monthly process: reviewing around 100 PDF documents by hand, copying out the key fields, and assembling the results into a report. The work consumed many hours of expert time, limited how often it could be done, and was inherently prone to human error.
EFL wanted to remove the manual bottleneck without compromising on the standards required by its banking-group governance: alignment with internal AI, cloud, and security committees, plus RODO obligations including anonymization of personal data. Softwise.AI was asked to design and deliver a production-grade system that would automatically extract structured financial data from leasing documents, hand back standardized outputs, and pass the organisation’s full compliance review.
{Key Challenges}
Why template-based OCR failed across 40+ document formats?
The project had to solve a set of interlocking problems that ruled out a simple off-the-shelf or template-based approach:
Manual, slow competitive monitoring
Monthly analysis of around 100 documents was performed by hand. The process was time-consuming, error-prone, and impossible to scale or run more frequently
Heterogeneous, messy input data
Documents from more than 40 sources arrived in very different formats, layouts, and terminologies - often as scanned or photographed pages - making traditional template-based OCR brittle and expensive to maintain
Strict security and compliance requirements
As part of a banking group, the solution had to satisfy internal AI, cloud, and security committees as well as RODO, including anonymization of personal data and controlled access to cloud resources
Production-grade robustness from day one
The system had to go well beyond prototype: controlled retries, quality monitoring, predictable processing times, and clear operational procedures for both business users and IT.
{Process}
How we built the data extraction pipeline in 5 steps?
Softwise.AI delivered the engagement as a focused build, designed to move from a real-world problem to a working production pipeline without losing momentum on compliance approvals.
1. Scoping and data understanding
Working with EFL's analysts, the team reviewed real document samples, identified the fields that actually mattered for monthly reporting, and decided where to focus extraction effort - including a conscious decision to concentrate on first-page content, where the vast majority of relevant information sits.
2. Architecture and security alignment
The pipeline was designed on Azure with EFL's IT, security, and AI governance bodies involved from the start. Approval processes were run in parallel rather than sequentially, and a local anonymization solution was chosen specifically to support audits and pass internal review.
3. LLM extraction and prompt tuning
Rather than rigid templates, the team adopted LLM-based extraction with prompts tuned to leasing terminology. Prompts were iteratively refined against real documents to handle widely varying layouts and language.
4. Robustness engineering
A retry mechanism was added to automatically reprocess problematic files up to four times, with the best result selected by confidence score. Parallelization (up to 10 files at once) and Kafka-based orchestration brought processing time down by 89%.
5. Operationalization
The system was wired into a simple, business-friendly workflow: upload to an Azure Blob inbox, trigger by email, receive results by email. Documentation, monitoring, and operational procedures were delivered alongside the pipeline.
Solution
Softwise.AI delivered a production-ready extraction and analysis pipeline for leasing documents, combining Azure cloud services, large language models, and domain-specific validation logic.
A business workflow built around the analyst
The user uploads documents to a dedicated Azure Blob inbox, then sends a trigger email from an authorized address to start the batch. When processing completes, results are emailed back as JSON files (a short version with extractions and a full version with confidence scores and metadata) plus an Excel file formatted for quick human verification. A monthly batch of raw PDFs becomes a complete report in minutes, with no manual copy-paste or scripting.
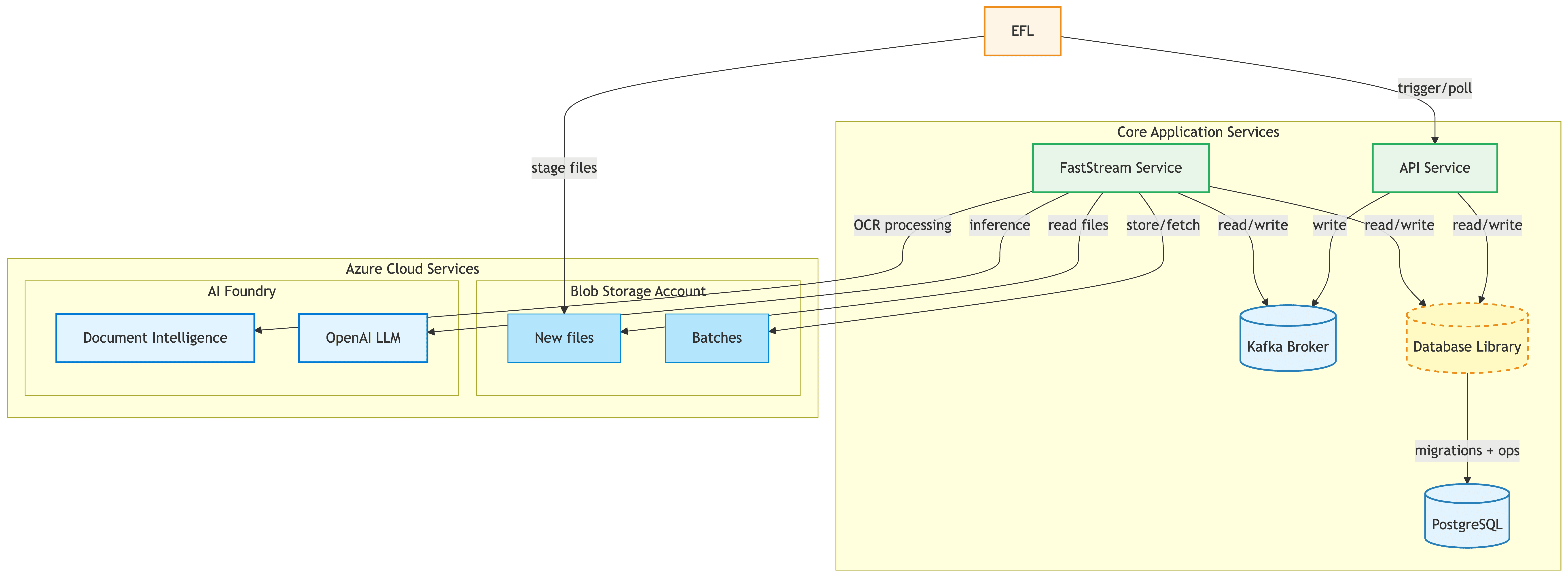
LLM-based extraction tuned to the domain
OCR and model inference together extract every required field using prompts engineered for leasing terminology. Mandatory-field checks and confidence scoring run on every output, and the LLM approach handles widely varying real-world layouts that template-based OCR could not.
Designed for predictable production runs
Processing is deliberately batch-oriented and optimized for monthly cycles rather than real-time use. Under the hood, a retry mechanism reprocesses problematic files up to four times and picks the best result by confidence score, while parallel workers keep throughput high.
Compliance and security by design
Local anonymization, controlled cloud access, and full alignment with EFL's AI, cloud, and security committees were not bolted on at the end - they shaped the architecture from the first design session.
{Results}
94% extraction accuracy and 100 files processed in 10 minutes
The pipeline was evaluated against agreed targets and exceeded each of them:
Extraction accuracy - Target 85%, achieved 94% on key data fields across test documents.
Processing time for a 100-file batch - Target under 15 minutes, achieved 10 minutes.
Rejected file rate - Target under 15%, achieved 10.5%.
System availability - Target above 95%, achieved 99%.
Scale headroom - 188 PDFs processed in 13 minutes (around 40 seconds per file with ten parallel workers); the pipeline remains stable well above expected monthly load.
{Business impact}
98.75% less manual work for EFL analysts
Manual work eliminated. Specialist time spent on monthly extraction is reduced by an estimated 98.75%, freeing analysts for higher-value work.
Faster market insights. Monthly reports can now be produced in minutes, enabling more frequent and timely reviews of market conditions.
Standardized, analysis-ready data. Every document is transformed into a consistent JSON format, making downstream analytics and integration with the data warehouse straightforward.
Scalability by design. The pipeline can handle at least three times the planned volume without infrastructure changes - room to expand scope without re-engineering.
Higher confidence in decisions. 94% extraction accuracy combined with per-field confidence scores gives EFL a solid factual base for pricing and strategic decisions.
{Key recommendations}
5 rules for automating document-heavy work under compliance
The project also surfaced a set of principles that apply to any organization automating document-heavy processes under regulatory constraint:
Choose LLMs over rigid templates for documents with wildly varying layouts. Prompt tuning scales far better than rule maintenance.
Engineer for production from day one. Retries, confidence-based selection, monitoring, and clear operational procedures matter more than peak accuracy on a clean sample.
Run compliance in parallel, not sequentially. Bringing IT, security, and AI governance in at the start - rather than at the end - keeps group projects on schedule.
Pick batch over real-time when the business case is batch. Optimizing for predictable monthly runs gave EFL faster, cheaper, and more reliable processing than a real-time architecture would have.
Draw a clean boundary on edge cases. Excluding a small number of extremely exotic document types - where the cost of handling outweighs the business value - kept the system economically viable.
SUMMARY
Softwise.AI delivered a production-ready, compliance-aligned data extraction system that replaced a manual monthly process at EFL with a fast, accurate, and scalable pipeline. With 94% extraction accuracy, a 10-minute processing time for 100 files, and full alignment with group governance, EFL is now positioned to scale its competitive intelligence capabilities and base strategic decisions on high-quality, standardized data.

TESTIMONIAL
We assess our cooperation with Softwise.AI very positively. The company has demonstrated strong technological expertise, good work organization, and a responsible approach to task execution. The solution not only delivers business value (98%+ shorter extraction time compared to the initial process) but at the same time is fully compliant with our strict regulatory requirements, compliance and data privacy policies.

Krzysztof Polcyn
Director of Innovation, EFL